Warp Processing
Warp processing is the process of dynamically converting a typical software intstructions binary into an FPGA circuit binary for massive speedups ("warp speed"). FPGAs are a relatively new type of IC (invented in the late 1980s, now commercially mature and affordable) that supports highly-parallel computations from the arithmetic up to the process level, at the cost of larger size and slower clock frequency. While some applications exhibit no speedup on FPGAs (or even slowdown), other highly-parallelizable applications, such as image processing, encryption, encoding, video/audio processing, mathematical-based simulations, and much more, may exhibit 2x, 10x, 100x -- even 1000x speedups compared even to fast microprocessors. Energy savings may also result. By conducting optimizations at runtime, warp processing has the advantages of eliminating tool flow restrictions and extra designer effort associated with traditional compile-time optimizations, and supports the extremely important portable binary concept that is so essential in modern computing. The warp processing project began in 2001. Major achievements so far have included:
- Demonstration that aggressive decompilation can, in creating a control/dataflow graph, recover enough high-level information (e.g., loops, arrays, subroutines) from microprocessor binaries to enable synthesis of circuits that are competitive in size and speed to circuits synthesized directly from high-level source code -- even when the binaries are compiled with high-optimization levels. (Work was done by Greg Stitt, Ph.D. UCR CS&E 2007, now an assistant professor of ECE at the University of Florida, Gainseville).
- Development of a complete synthesis flow starting from a control/dataflow graph -- high-level synthesis, logic synthesis, and FPGA technology mapping, placement, and routing -- for *fast* synthesis suitable for runtime use. 10x improvements in speed and memory use were obtained vs. commercial tools, at the cost of about 30% penalty in circuit speed and size. An FPGA fabric tuned for fast synthesis was also created. (Work was done by Roman Lysecky, Ph.D. UCR CS&E 2004, now an assistant professor of ECE at the University of Arizona).
Portable format for temporal/spatial computing Present work focuses of moving beyond standard microprocessor binaries to a new portable binary format suitable for future platforms having multiple microprocessors coupled with FPGAs. Such a portable format must include not only the sequential constructs (branches, loops, assignments, subroutines) suitable for microprocessors, but also spatial constructs (component X is connected to component Y, data Z is stored in memory M) that capture clever human-designed parallel computing concepts suitable for FPGAs. This format, akin to Java bytecode or Microsoft's CIL bytecode for microprocessors, can be executed initially on an emulator, but then just-in-time compiled (using the above-mentioned decompilation/synthesis techniques) to ultra-fast execution on a platform's available microprocessors and FPGA fabric. (Work is being done by UCR Ph.D. student Scott Sirowy).
When synthesizing an application to a microprocessor/FPGA platform, many implementation choices exist. For example, an application may have multiple regions each of which can be sped up by a variety of FPGA coprocessing circuits -- which particular combination of coprocessors should be used to best utilize available FPGA? Or, if applications come and go, when should coprocessors be loaded or removed (which are time-consuming tasks) to/from the FPGA? If a microprocessor's cache can be resized, how and when should it be resized based on the history of executing applications? We can view a platform able to modify itself as a transmuting multiprocessors platform. (Work is being done by UCR Ph.D. student Chen Huang).
Likewise, architectures mapped to microprocessor/FPGA platforms tend to have numerous parameters that can be tuned to yield performance/energy improvements for a particular set of executing applications (e.g., one set may 2x faster if we just alter some cache parameters like line size). Given numerous parameters, exploring the design space is difficult. Design of Experiments techniques can search the space very efficiently, whether that search is done dynamically (as above), or statically (i.e., offline, or during compile time). (Work is being done by UCR Ph.D. student David Sheldon).
The above work has been supported by the National Science Foundation (awards CNS-0614957, CCR-0203829) and the Semiconductor Research Corporation (2005-HJ-1331), with further assistance from Xilinx, Intel, Freescale, and IBM.
Sample key publications
For a complete list and the most recent publications on the above subjects, look for papers by the above-listed people on Frank Vahid's publications page.
S.Sirowy, G. Stitt and F. Vahid.
Symposium on Field-Programmable Gate Arrays (FPGA), 2008.
R. Lysecky and F. Vahid.
ACM Transactions on Embedded Computer Systems (TECS), 2008 (to appear).
G. Stitt and F. Vahid.
Int. Conf. on Hardware/Software Codesign and System Synthesis (CODES/ISSS), 2007.
F. Vahid, G. Stitt, and R. Lysecky.
IEEE Computer, Vol. 41, No. 7, July 2008, pp. 40-46.
ACM Transactions on Design Automation of Electronic Systems (TODAES), 2007.
R. Lysecky, G. Stitt, F. Vahid
ACM Transactions on Design Automation of Electronic Systems (TODAES), July 2006, pp. 659-681.
G. Stitt, F. Vahid, W. Najjar
IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Nov. 2006, pp. 716-723.
G. Stitt, F. Vahid
IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Nov. 2005, pp. 547-554.
G. Stitt, F. Vahid, G. McGregor, B. Einloth
International Conference on Hardware/Software Codesign and System Synthesis (CODES/ISSS), Sep. 2005, pp. 285-290.
Below are our early papers on the subject -- likely the first papers to introduce the concepts of synthesis from binaries, on-chip logic synthesis, and dynamic hardware/software partitioning (warp processing).
G. Stitt, R. Lysecky, F. Vahid
Design Automation Conference (DAC), 2003, pp. 250-255.
Dynamically partitioning an executing software application onto on-chip FPGA is not only possible, but quite effective.
R. Lysecky, F. Vahid and S. Tan
IEEE Symposium on Field-Programmable Custom Computing Machines (FCCM), 2005, pp. 57-62
G. Stitt and F. Vahid
Design Automation and Test in Europe (DATE), March 2005, pp. 396-397
R. Lysecky, F. Vahid
Design Automation Conference (DAC), 2003.
Executing a lean form of logic minimization on-chip is feasible and has several immediate applications in networking.
G. Stitt and F. Vahid
IEEE/ACM International Conference on Computer Aided Design, November 2002, pp. 164-170.
Performing hw/sw partitioning on software binaries can achieve results similar to a compiler-based approach without imposing restrictions on the high-level language or compiler. Binary-level partitioning also supports partitioning of library code, legacy code, and hand-optimized assembly.
More information
Warp Processing Press Release (Oct 2007)
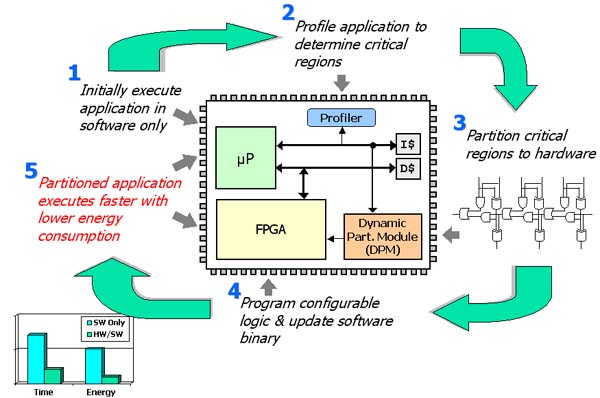
The functionality of a warp processor is illustrated in the figure shown above. Initially, software executes on the microprocessor. As the software executes, a profiler monitors the software to determine regions of code responsible for a large percentage of execution time (which we call critical regions). Once the profiler has identified critical regions, the warp processor will partition the critical regions to hardware. Hardware for the critical regions is synthesized in the DPM (dynamic partitioning module). The DPM then programs the configurable logic to implement the synthesized hardware. The DPM also updates the software binary so that the hardware will be used during execution. Finally, the partitioned application begins executing much faster while consuming less energy.
Warp Tools
Hardware/software partitioning tools typically execute on power workstations with gigabytes of memory and extremely fast processors. Warp processors execute these same tools in an on-chip environment. To make on-chip execution possible, Warp processor have specialized tools that target the most common regions implemented in hardware, generally small, frequent loops. These specialized tools are designed to be very lean, requiring orders of magnitude less memory and execution time.
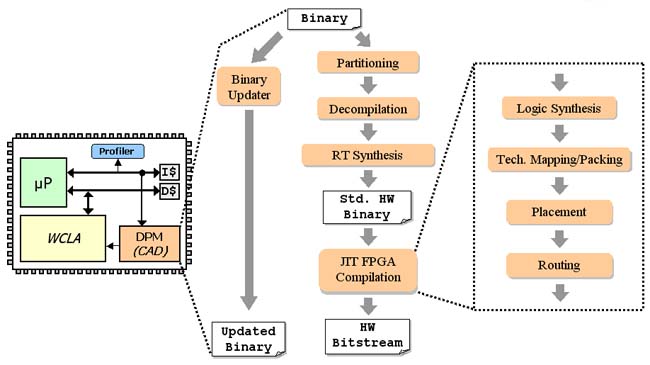
The tool flow implemented by Warp processors is shown in the adjacent figure. Initially, partitioning selects the critical regions identified by the on-chip profiler that are appropriate for hardware. Next, decompilation recovers high-level constructs (loops, arrays, etc.) to create a representation of the code that is more suitable for synthesis. The decompiled representation is then passed to the register-transfer synthesis tool that creates a standard hardware binary. Next, JIT FPGA compilation converts the standard binary into a binary for the specialized WCLA (Warp Configurable Logic Architecture). During JIT FPGA compilation, logic synthesis performs logic optimizations to reduce the number of gates required by the hardware. Technology mapping handles mapping the gate-level netlist onto configurable logic in the WCLA. Place and route determines all connections in the WCLA and then outputs a bitstream that programs the WCLA. The binary updater modifies the software binary by replacing the original software loops with hardware initialization and communication code.
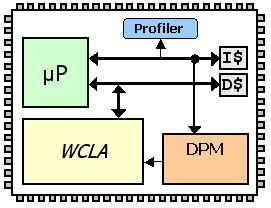
Warp Architecture
|
The Warp processor architecture consists of several components: a main microprocessor, an on-chip profiler, a dynamic partitioning module (DPM), and a specialized warp configurable logic architecture (WCLA). The main microprocessor executes the software partition. The profiler monitors instruction fetches to determine the most frequently executed regions of the software. The DPM is responsible for executing all CAD tools described earlier. The DPM consists of an additional microprocessor and a small amount of memory for executing the CAD tools. The WCLA (Warp Configurable Logic Architecture) is a specialized configurable logic fabric that allows for very efficient place and route operations. |
Results
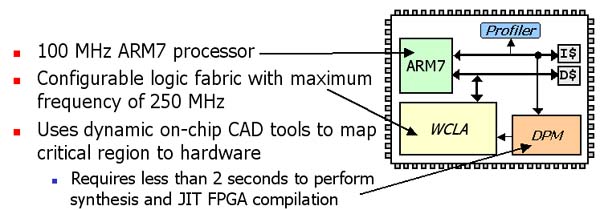
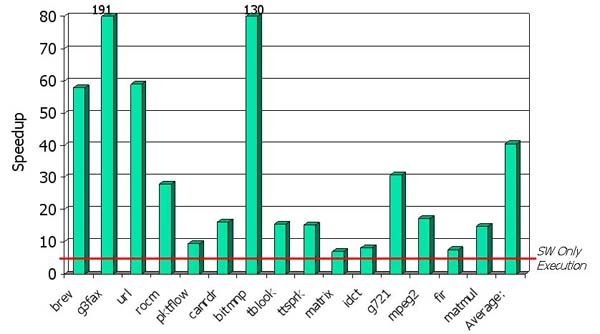
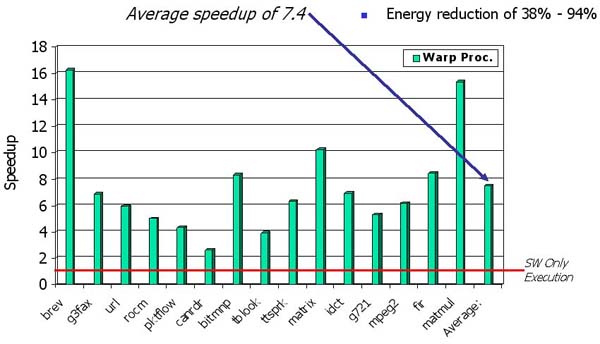
The charts shown below illustrate the speedup achievable by Warp processors. The first chart shows the experimental setup. For these experiments, the main microprocessor consisted of an ARM7 running at 100 MHz. The DPM used an additional ARM7 to execute the CAD tools, which executed in under two seconds. The second chart shows the speedups of the single most frequent region when implemented in hardware compared to the software-only execution of the same region. The final chart shows overall application speedup, averaging 7.4, after warp processing has implement multiple critical regions in hardware. The energy savings for the same experiements ranged from 38% to 94%.
The benchmarks used in the experiements were selected from PowerStone, EEMBC, NetBench, and our own benchmark suite.
Experimental Setup
Single Kernel Speedup
Overall Speedup
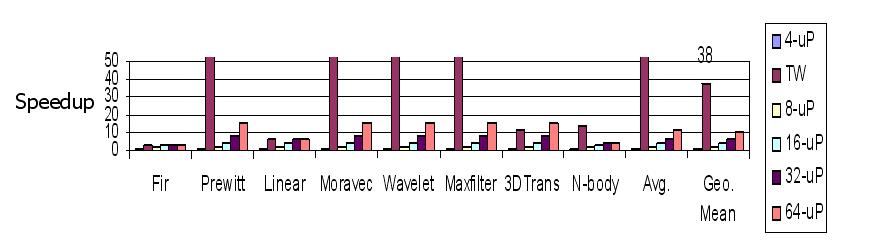
Thread Warping Speedup
The following shows results of executing highly-parallelizable benchmarks using warp processing (with each entire threads being mapped to FPGAs) versus execution on 4-microprocessor (uP), 8, 16, 32, and 64 micrprocessor systems. Even compared to 64 processor systems with optimistic communication assumptions, warp processing of threads still achieves huge speedups.
People
- Dr. Frank Vahid - Principal Investigator
-
Scott Sirowy - Ph.D. Student
- David Sheldon - Ph.D. Student Chen Huang - Ph.D. Student
- Roman Lysecky - Former Ph.D. Student (now UA prof)
- Greg Stitt - Former Ph.D. Student (now UF prof)