| Optimizing Multi-dimensional MPI Communications on Multi-core Architectures |
|
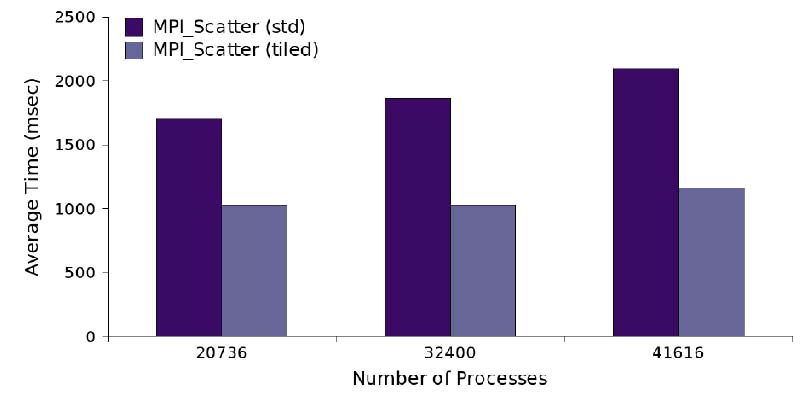 Multi-dimensional MPI communications, where MPI communications have
to be performed in each dimension of a Cartesian communicator,
have been frequently used in many of today's high performance
computing applications. While single-dimensional MPI communications
have been extensively studied and optimized, little optimization
has been performed for multi-dimensional MPI communications.
Multi-dimensional MPI communications, where MPI communications have
to be performed in each dimension of a Cartesian communicator,
have been frequently used in many of today's high performance
computing applications. While single-dimensional MPI communications
have been extensively studied and optimized, little optimization
has been performed for multi-dimensional MPI communications.
In this research, we consider all communications in
all dimensions together
and optimize the total communication time in all dimensions.
We demonstrate that the default process-to-core mappings in today's
state-of-the-art MPI implementations provided by MPI_Init()
and MPI_Cart_create() are often sub-optimal for multi-dimensional
communications. We propose an application-level tile-based
multicore-aware process-to-core re-mapping scheme that is capable
of achieving optimal performance for multi-dimensional
communications. By re-mapping computational processes to
hardware cores using a tiling technique, the communications
are re-distributed to minimize the inter-node communications.
The proposed technique improves the performance by up to 80%
over the default Cartesian topology built by Cray's MPI
implementation MPT 3.1.02 on the world's current fastest
supercomputer, Jaguar, at Oak Ridge National Laboratory.
|
| Fault Tolerant Extreme Scale Computing: An Algorithmic Approach |
|
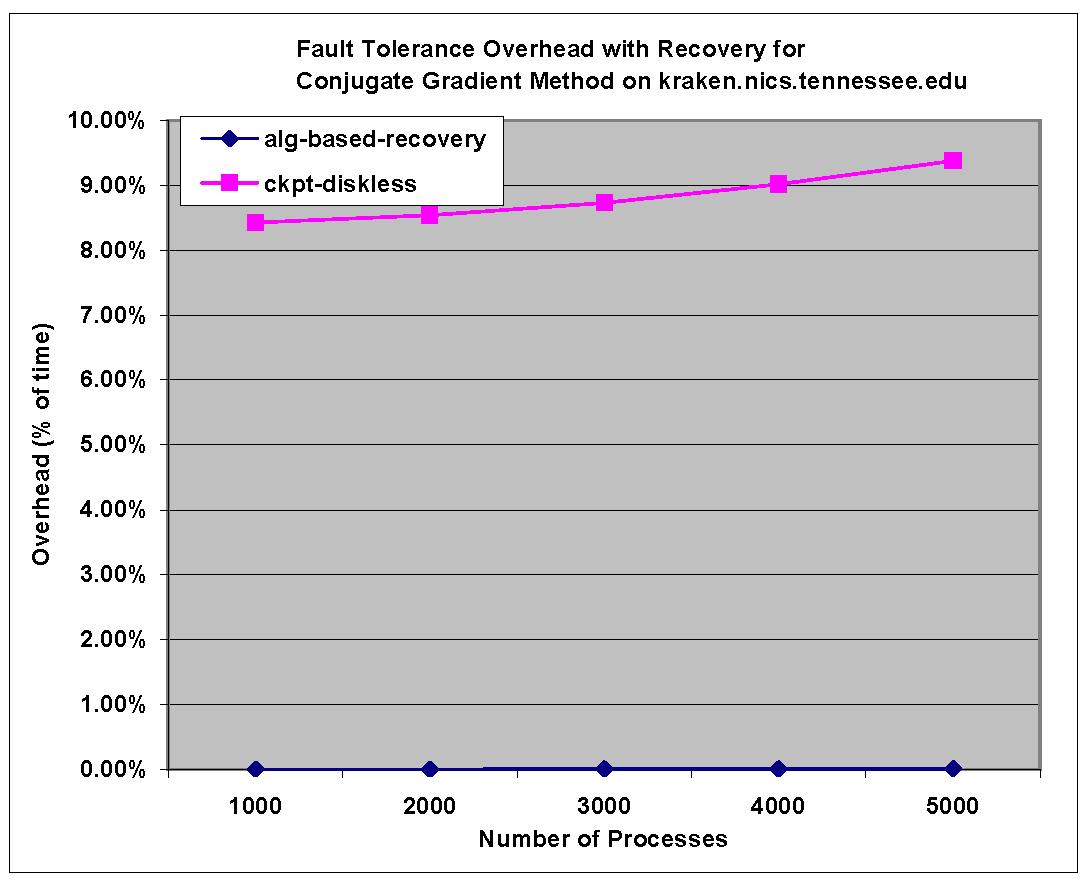 In today's high performance computing practice,
fail-stop failures, where where a failed process stops working, are often tolerated by checkpointing/restart. While checkpointing/restart is usually very general and can often be used in many types of systems and to a wide range of applications, it often introduces a considerable overhead especially when computations reach petascale and beyond or applications modify a large mount of memory between two consecutive checkpoints.
In today's high performance computing practice,
fail-stop failures, where where a failed process stops working, are often tolerated by checkpointing/restart. While checkpointing/restart is usually very general and can often be used in many types of systems and to a wide range of applications, it often introduces a considerable overhead especially when computations reach petascale and beyond or applications modify a large mount of memory between two consecutive checkpoints.
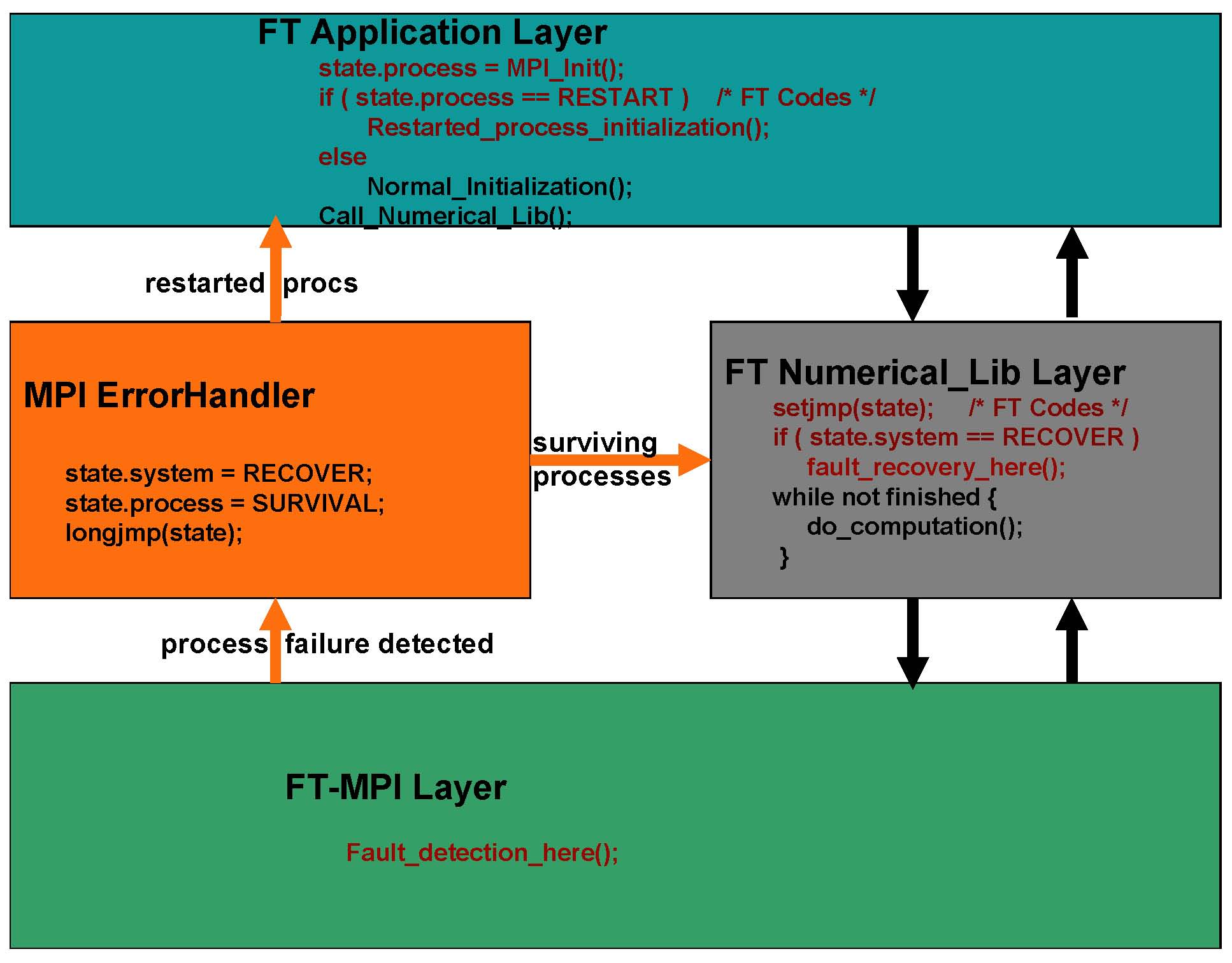
In this research, we propose to design algorithm-based recovery techniques to tolerate fail-stop failures according to the specific characteristics of an application. While they are challenging to design, algorithm-based recovery schemes often introduce a much less
overhead than the more general periodical checkpointing technique.
Because no expensive periodical checkpointing is necessary during the whole computation and no roll-back is necessary after a failure, the proposed algorithm-based recovery techniques are often highly scalable and have a good potential to scale to extreme scale computing and beyond.
|
| Numerically Stable Real Number Error/Erasure Correcting Codes |
|
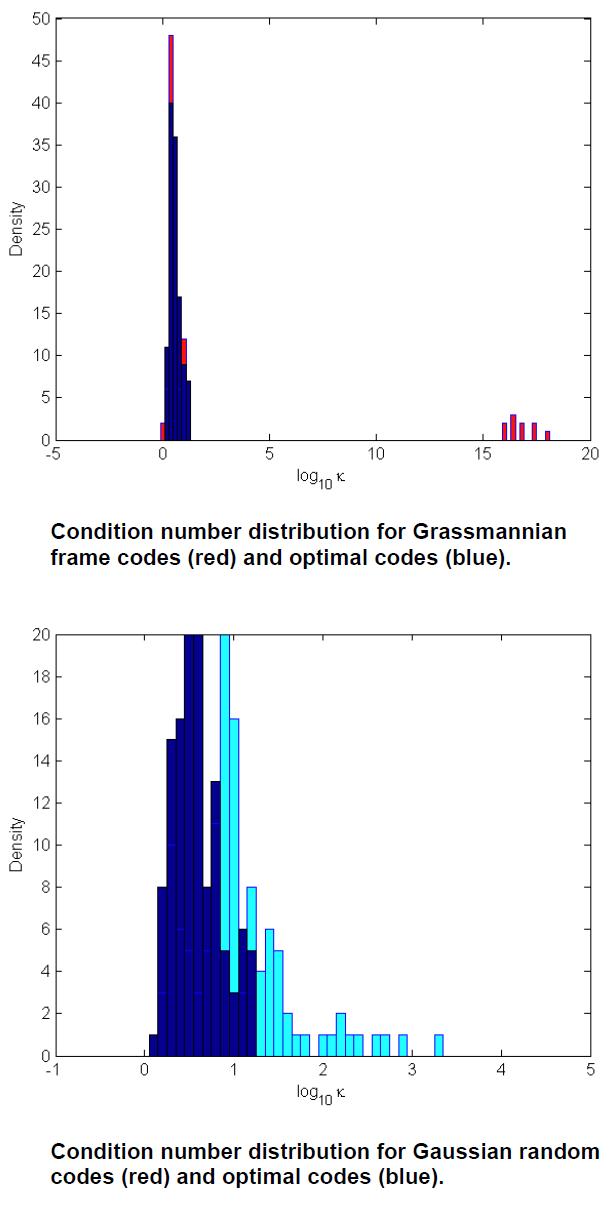 Error/Erasure correcting codes are often defined over finite fields. However, in many applications, codes defined over finite fields may not work and codes defined over real-number (or complex-number) fields have to be used to correct errors/erasures. It has been proved in previous research that for every error/erasure correcting code defined over finite field, there is a corresponding code in the real-number field. However, due to the round-off errors introduced by the floating point representation of real numbers in today high performance computer architecture, it is often inappropriate to just directly use the finite field error/erasure correcting techniques to correct errors/erasures in real numbers.
Error/Erasure correcting codes are often defined over finite fields. However, in many applications, codes defined over finite fields may not work and codes defined over real-number (or complex-number) fields have to be used to correct errors/erasures. It has been proved in previous research that for every error/erasure correcting code defined over finite field, there is a corresponding code in the real-number field. However, due to the round-off errors introduced by the floating point representation of real numbers in today high performance computer architecture, it is often inappropriate to just directly use the finite field error/erasure correcting techniques to correct errors/erasures in real numbers.
In this research, we explore numerically stable algorithms to correct errors/erasures in floating-point numbers through research in three areas: i). Random error/erasure correcting codes; ii). Error correcting via linear programming; and iii). Techniques to improve stability. We also work on developing the numerically best floating-point error/erasure correcting codes.
|
| Large Scale Reservoir Simulation through Petascale Supercomputing (collaborating with the Petroleum Engineering Department at the Colorado School of Mines) |
|
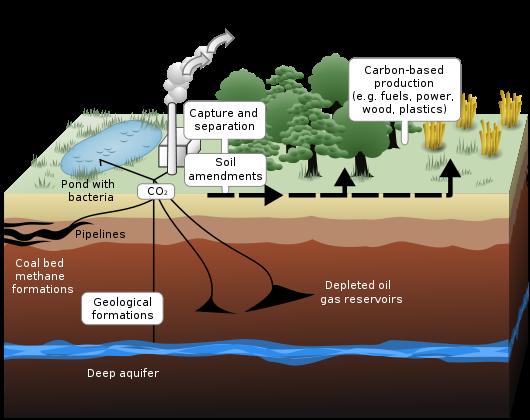 To address the increasing concerns regarding greenhouse gas emission and its impact on global climate, CO2 geologic sequestration, i.e., injecting large amounts of CO2 into deep subsurface formations for long-term storage, is considered to be among the most promising, viable approaches for near-term implementation.
To evaluate whether geologic storage is a viable technology for reducing atmospheric emissions of CO2, it is necessary to understand and investigate the conditions under which large amounts of CO2 can be injected and stored safely for a long time (centuries to millennia) in geologic formations, which is controlled by complicated processes of CO2 multiphase flow and transport, coupled with site-specific geothermal, geochemical and rock mechanical effects.
To address the increasing concerns regarding greenhouse gas emission and its impact on global climate, CO2 geologic sequestration, i.e., injecting large amounts of CO2 into deep subsurface formations for long-term storage, is considered to be among the most promising, viable approaches for near-term implementation.
To evaluate whether geologic storage is a viable technology for reducing atmospheric emissions of CO2, it is necessary to understand and investigate the conditions under which large amounts of CO2 can be injected and stored safely for a long time (centuries to millennia) in geologic formations, which is controlled by complicated processes of CO2 multiphase flow and transport, coupled with site-specific geothermal, geochemical and rock mechanical effects.
This project aims to develop a comprehensive reservoir simulator to model the non-isothermal multiphase flow and transport of CO2 in saline aquifers with heterogeneity, anisotropy, and fractures and faults, coupled with geochemical and geomechanical processes that would occur during CO2 geological sequestration (GS) processes. The designed model will utilize petascale computations to allow rapid and efficient modeling assessment of GS injection strategies and long-term prediction of GS system behavior.
|
| Highly Scalable Fault Tolerance Schemes for Petascale Earthquake Simulations (collaborating with the University of Southern California and the San Diego Supercomputer Center) |
|
 The Anelastic Wave Propagation, AWP-ODC, independently simulates the dynamic rupture and wave propagation that occurs during an earthquake. Dynamic rupture produces friction, traction, slip, and slip rate information on the fault. The moment function is constructed from this fault data and used to initialize wave propagation.
A staggered-grid finite difference scheme is used to approximate the 3D velocity-stress elastodynamic equations. The user can has the choice of modeling dynamic rupture with either the Stress Glut (SG) or the Staggered Grid Split Node (SGSN) method. The user has the choice of two external boundary conditions that minimize artificial reflections back into the computational domain: the absorbing boundary conditions (ABC) of Cerjan and the Perfectly Matched Layers (PML) of Berenger. AWP-ODC has been written in Fortran 77 and Fortran 90. The Message Passing Interface enables parallel computation (MPI-2) and parallel I/O (MPI-IO).
The Anelastic Wave Propagation, AWP-ODC, independently simulates the dynamic rupture and wave propagation that occurs during an earthquake. Dynamic rupture produces friction, traction, slip, and slip rate information on the fault. The moment function is constructed from this fault data and used to initialize wave propagation.
A staggered-grid finite difference scheme is used to approximate the 3D velocity-stress elastodynamic equations. The user can has the choice of modeling dynamic rupture with either the Stress Glut (SG) or the Staggered Grid Split Node (SGSN) method. The user has the choice of two external boundary conditions that minimize artificial reflections back into the computational domain: the absorbing boundary conditions (ABC) of Cerjan and the Perfectly Matched Layers (PML) of Berenger. AWP-ODC has been written in Fortran 77 and Fortran 90. The Message Passing Interface enables parallel computation (MPI-2) and parallel I/O (MPI-IO).
In this research, we will explore the characteristics of AWP-ODC
and develop algorithm-based recovery techniques for AWP-ODC.
|
| HPC Windows: Reliable High Performance Computing for Windows Platforms (collaborating with Microsoft) |
|
 While Microsoft Windows is extremely popular in the personal computer (PC) market, the use of the platform (including the newly released Windows HPC server 2008) is very limited in HPC field. After interviewing a number of HPC practitioners, we found the main reasons for this phenomenon include: 1). existing HPC practitioners have been used to do HPC under Unix-like platforms for many years and tend to stay with the platforms they are already familiar with; 2). Many HPC software libraries and tools available on Unix-like platforms are not available on Windows HPC Server; 3). Despite the increased stability of the new generation of Windows HPC platform, Windows is still not so stable as Unix-like platforms.
While Microsoft Windows is extremely popular in the personal computer (PC) market, the use of the platform (including the newly released Windows HPC server 2008) is very limited in HPC field. After interviewing a number of HPC practitioners, we found the main reasons for this phenomenon include: 1). existing HPC practitioners have been used to do HPC under Unix-like platforms for many years and tend to stay with the platforms they are already familiar with; 2). Many HPC software libraries and tools available on Unix-like platforms are not available on Windows HPC Server; 3). Despite the increased stability of the new generation of Windows HPC platform, Windows is still not so stable as Unix-like platforms.
The goal of this joint partnership between Microsoft and University of California, Riverside (CSM) is to: 1). create an opportunity for CSM students to learn how to develop HPC applications on Windows HPC Server;
2). develop highly scalable checkpointing techniques and software for Windows so that Windows HPC applications can tolerate the crash of the platform.
|
