Because the cache described in 7.9 has one-word blocks, it makes use of temporal (how?), but not of spatial locality. In contrast, cache in 7.10 has four-word blocks (reads four words at a time, properly alligned, e.g. four words containing word 2 are 0,1,2,3, four words containing 5 are 4,5,6,7), so by loading the neighborhood of a word together with a particular word, it attempts to improve the hit rate using spatial locality.
Another thing to pay attention to is how to find an item in cache, and how it differs in 7.9 and 7.10. If you have one-word blocks, then the address is "split" into two parts (no splitting really occurs, but you can think about it that way):
| tag | index |
The number of bits in the index part is how many bits you
need to distinguish between the blocks (if you have 32 blocks, you
need 5 bits, remaining 25 bits become the tag, and together
the tag and the index uniquely determine an
addres in memory, so tags are used to check if a
particular location in cache really contains the word/byte that we
need).
If you have a block of size greater than one, then you need to
identify which block an address would be mapped to, but also where
in the block the word/byte is (this is called the offset).
| tag | index | of |
Details can be found in Dr. Bhuyan's lecture slides. The important thing is to understand that depending on the design of the cache, the total length of the address will be partitioned in several parts, and their lengths will be determined by the sizes of blocks, total main memory, total cache memory, etc. This line of reasoning will be useful for solving 7.39.
7.12 asks you to understand the overhead involved with maintaining the cache, for a simple cache variant (Intrinsity):
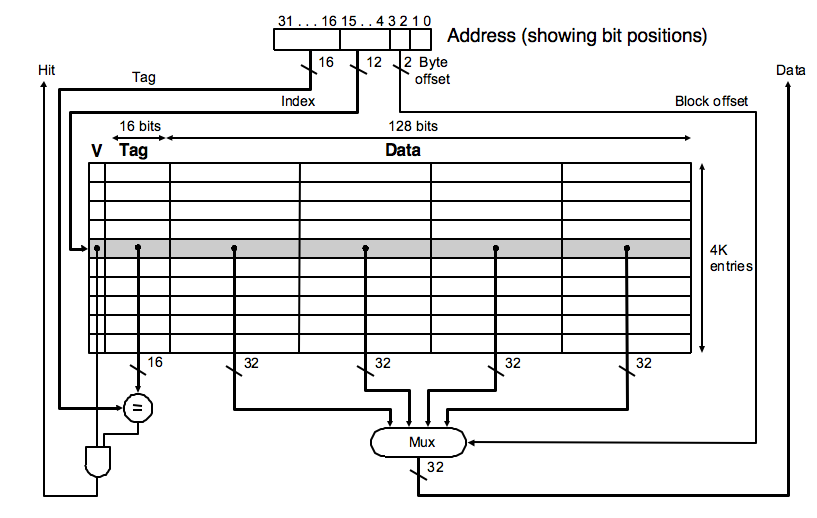
Note how the 32-bit address is partitioned, and make the connection between the design of the cache and the fields in the address.
In 7.17, 7.18, 7.19, the definition of miss penalty is "the time to transfer one block from main memory to the cache." Note that the time to read the data from cache is not included, which results in a formula for average access time slightly different from the one in the lecture slides:
AMAT = Hit time + Miss Rate x Miss PenaltyUse this formula to solve the homework. Note that 7.18 and 7.19 make comparisons with the result from 7.17, which is a direct application of the AMAT formula (virtually, just plug in the numbers).
The primary method of achieving higher memory bandwidth is to increase the physical or logical width of the memory system. In the following figure, the basic design, where all components are one word wide (leftmost), is improved in two ways. The middle setup uses a wider memory, bus and cache; the rightmost setup has a narrow bus, narrow cache, and interleaved memory.
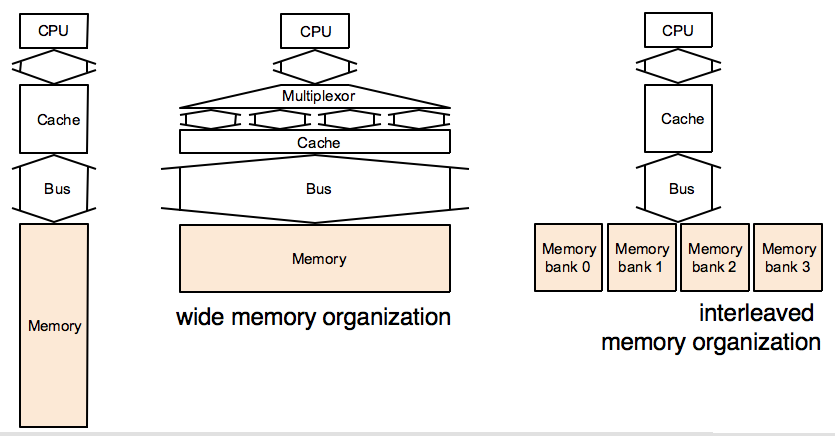
7.14 and 7.20 ask you to understand those designs, and quantitatively describe the differences between the them. Also, think about when can several blocks in the rightmost design be read at once, and when will there be a bank conflict.
Regarding 7.20, in an interleaved memory organization you can send more than one request for a memory location at once (up to how many banks you have, in this case 4). However, you can send only one request to any given bank at a time -- bank conflict is when you try to send two requests for memory locations in the same bank.
To illustrate this with an example: say, the processor requests memory locations 8, 19, 13 and 14. These would be in memory banks (8%4=) 0, (19%4=) 3, (13%4=) 1, and (14%4=) 2. Memory banks you are using are 0,1,2,3, so there are no bank conflicts.
However, if the processor would request 8, 12, 13, 14, they would be in (8%4=) 0, (12%=4) 0, (13%4=) 1, and (14%4=) 2, so because 8 and 12 would both be in the same memory bank (0), there would be a bank conflict, and you could not proceed with all four as you did in example 1, but you could send only the request for 8 in one round, and then in the next round you would send requests for 12, 13, 14, and potentially the next request in the sequence, if it does not cause a bank conflict.
Finally, 7.35 requires an understanding of the differences between direct mapping and set-associative caches.