UCR - CS 242 - Winter 2024
Instructions: Submit paper in Canvas by 2/24. This is individual assignment. No handwritten submissions allowed.
Exercise A
Consider the following document D, taken from a collection C.
"The University of California, Riverside is one of 10 universities within the prestigious University of California system, and the only UC located in Inland Southern California. Widely recognized as one of the most ethnically diverse research universities in the nation."
Consider the following two queries:
-
Q1: university Riverside
-
Q2: diverse university
Characteristics of collection C are as follows:
-
# docs in collection C: 10000
-
# docs in C that contain "Riverside": 100
-
# docs in C that contain "university/ies": 500
-
# docs in C that contain "diverse": 250
Compute the scores of Q1 and Q2 for D, using (a) BM25, and (b) Unigram Language Model (with smoothing method of your choice). Make and state any assumptions necessary, e.g., about the constants in BM25.
Exercise B
1) Write a program, in the language of your choice, to compute the PageRank scores of a graph.
Then, use your program to compute the PageRank score of each node in the graph below.
Show the output of your program for each iteration, that is, the PR scores for each iteration until it converges.
Use epsilon=0.01 as convergence threshold.
In how many iterations does the computation converge?
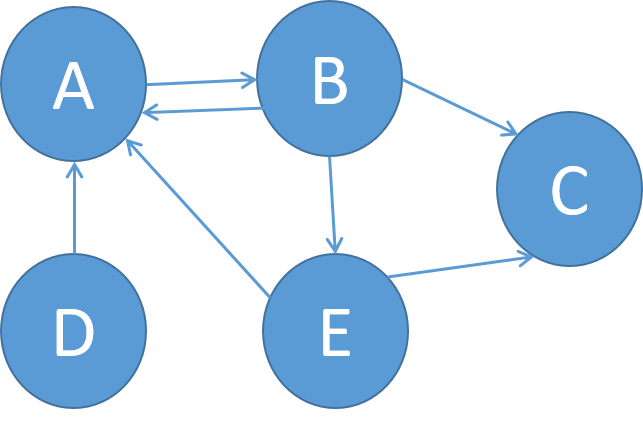
2) Repeat when only A is in the base set.
Exercise C
Show how MapReduce can be used to efficiently solve the following problem:
Given a collection of input documents, output all bigrams with pointwise mutual information greater than a constant T.
The pointwise mutual information of two words a,b is computed as P(a,b)/(P(a)P(b)), where P(a,b) is the probability they appear together as bigram a,b.
Write pseudocode for map and reduce functions.
How would you use a Combiner to optimize your program?Exercise D
r