Due Date: April 25, 2016. 100 points
Single person project. Do your own work!
In this project, you will add a journalling feature to a RAM disk filesystem provided. While this code is not based directly on any OS implementation, it does share the common concepts with UNIX filesystems. The full tarball for the project is available here.
Journalling (see Chapter 42 of OSTEP) improves the reliability of filesystems by logging a record of filesystem updates, so in the event of a computer system crash, one can determine unequivocally which updates should have been applied to the disk to keep the filesystem in a consistent state.
In particular, we will implement a slightly simplified version of the "Metadata Journaling" described on Page 14 of Chapter 42 (519 in the book). All the data structures referenced below are defined in cse473-filesys.h.
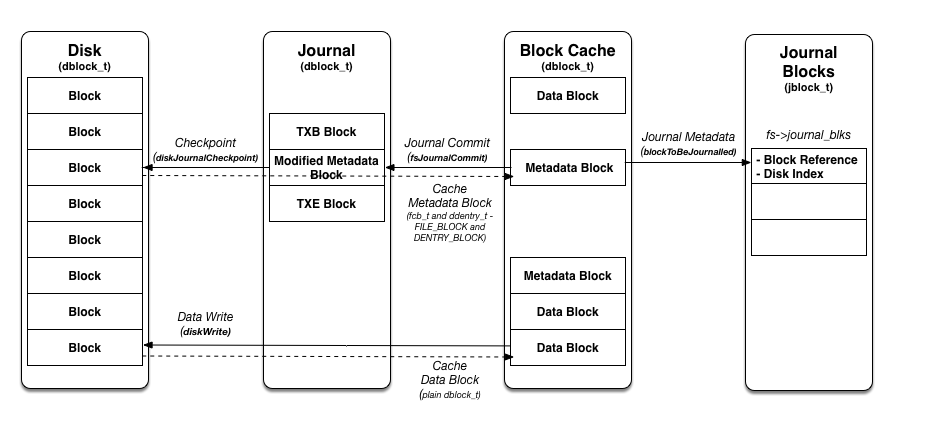
Data write: Write data to final location; wait for completion (the wait is optional; see below for details). This will be implemented in the function diskWrite, which is mostly completed. You have to perform the write operation to the "final location" on the disk (see Task #1).
Journal metadata record: Record the updates to metadata blocks in the filesystem cache (see below) to be journalled at commit time. In our simplified filesystem, there are commands that do not result in any metadata updates, so we instead record the blocks to be updated at commit time (step 3 below). Specifically, we record the block number and address of cached block to journal in the filesystem (global variable fs) field journal_blks. an instance of jblock_t, is implemented in the function blockToBeJournalled, which you will implement (Task #2). In addition, you will have to select the blocks to be journalled in the functions diskCreateDentry (create a new directory entry), diskCreateFile (create a new file control block), and diskGetBlock (add a new data block to the file). These functions are largely provided - you just have to identify the modified metadata blocks to journal and the associated disk block numbers by passing them to blockToBeJournalled (Task #3 - 3 instances).
Journal commit: Write the begin block and metadata (blocks to journal in fs->journal_blks recorded above in step 2) to the log; Write the transaction commit block (containing TxE) to the log; the transaction (including data) is now committed (no need to wait as we are writing a RAM disk). You must implement the function fsJournalCommit (Task #4), which uses the functions diskJournalCreateTxnBegin (for TXB), diskJournalCreateBlock (for each metadata block in fs->journal_blks), and diskJournalCreateTxnEnd. You must implement diskJournalCreateTxnEnd (Task #5), but use diskJournalCreateTxnBegin as a guide.
Checkpoint metadata: Write the contents of the metadata update to their final locations within the file system. You will write function diskJournalCheckpoint (Task #6). The TXB block data is a transaction (type txn_t), which has a field blknums, which stores an ordered sequence of indices for each journaled metadata block to the corresponding disk block numbers. That is how you figure out where to write the journalled block to on the disk.
Free: Later, mark the transaction free in journal superblock and free the journalled blocks. You will update the journal superblock metadata to indicate the free transactions in diskJournalCheckpoint (Task #7).
Conceptually, the filesystem uses journalling as shown below. A filesystem has performs updates on blocks in memory to improve performance in a block cache (our filesystem caches at the block level - old school). Thus, our filesystem reads a block, it writes that block into the cache memory and then file system operations are performed on the cached block. However, if the machine crashes, then the updates to the cached blocks will be lost, and the filesystem may become inconsistent (e.g., if some of the cached blocks have been committed to the disk). To prevent this, we add a journal to record the blocks that have been modified in a transaction. Disk updates then performed from the journal as a transaction. The above is true with the expection of file data updates, which are directly submitted to the corresponding disk blocks.
The file system structures are defined in the file cse473-filesys.h. A challenge is to understand the layout of these structures in blocks on the RAM disk. Below is a diagram outlining the blocks in the on-disk file system.
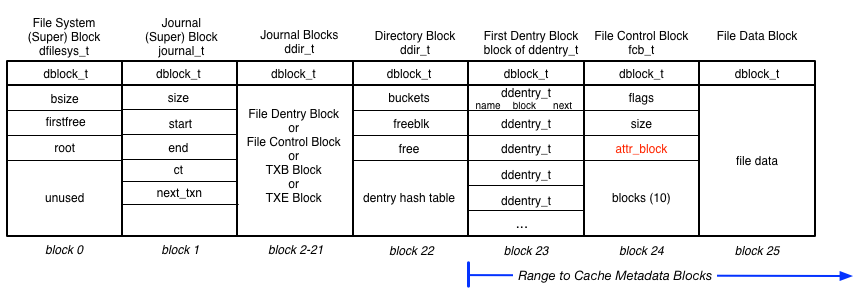
The first block (block 0) is the filesystem control block (fs superblock). All the blocks have a bit of block information at the beginning (dblock_t), but after that are the block contents. Block 0 specifies the number of blocks in the file system (bsize), the current first free block (firstfree), and the block number for the root directory (only directory). There is only one file system block. The code provided manages the filesystem control block.
Block 1 is the journal superblock (journal_t). The journal superblock includes the size (number of journal blocks), start and end indices of journalled blocks, count of blocks to be journalled, and the next transaction id to be assigned.
Blocks 2-21 are journal blocks to be used for the TXB, metadata, and TXE blocks for journaling. These blocks are used as a circular queue. The start and end values continue to increase as blocks are collected, so to find a specific journalled block you must use (index % FS_JOURNAL_BLOCKS). Each transaction applied to the journal must alway start with TXB block and end with a TXE block. The TXB block includes the transaction information (txn_t), such as the count (ct) of the number of metadata blocks (i.e., does not include TXB and TXE blocks), a transaction identifier (id), and the indices to the corresponding disk blocks (blknums) for the metadata journal blocks (in order).
Block 22 is the block that stores the directory. A directory refers to its hash table of directory entries (i.e., dentry) by its number of buckets which fill the remainder of the block and the location of the next free spot for a dentry (freeblk and free (slot)). Only the heads of the hash table are stored in the hash table. Each dentry has a next reference that is used to traverse the hash table lists. There are usually multiple directory blocks, but in this project there is only one.
Block 23 is the first dentry block, and it contains a set of dentries which each refer to a specific file by its name and (first) block. A next reference specifies the next entries to access for the dentry hash table. There can be multiple of these.
Block 24 is the file control block (FCB) which refers to the file meta data and actual data blocks. There are only 10 blocks in a file currently. There is one FCB per file.
Block 25 is a typical file data block. Other than the block header these blocks contain only file data. There should be lots of these.
In the assignment, you will run 5 command files in sequence: ./cse473-p3 your_fs cmdi, where cmdi is the ith command for (e.g., cmd1 for the first and cmd5 for the last). Included in the project tarball are a series of five output files (p3-out.cmdi) that show the expected responses for your file system code. This program is deterministic, so your output should match mine (bug disclaimer here).
Grading: