Download the code here.
Motivation
We required a benchmark that could be used to simulate reads on primary and secondary attribute values for benchmarking the performance of a key-value store that we are developing at UCR.
We also required a workload that would be similar to a real-world system. Chirp is designed to generate benchmarks that approximate the workload that Twitter's infrastructure handles. While it is easy to obtain write workloads for internet-scale systems, it is often not easy to obtain the read workload.
This is Chirp's contribution.
Get involved
We are always looking to improve Chirp. You can contribute by adding features and tests or by improving running time.
Please send us links to your contributions and we'll list them here for everyone's benefit.
Contact us at:
Overview
Provide Chirp with a file containing tweets (or any other JSON object with a timestamp), set your parameters and you can generate a benchmark file with read and write instructions. You can then use this benchmark file to simulate the desired workload for tests on your key value store.
We can simulate a Twitter-like write workload directly by using the timestamps in a sample of tweets. In addition, Chirp generates a Twitter-like read workload from the given sample. Chirp assumes that the (write) timestamps come from a Poisson distribution. It then generates read requests according to a Poission distribution. The parameter λ for the distribution of read requests is derived from the λ of the distribution of write requests and the reads-to-writes ratio. The reads-to-writes ratio is a parameter that is set by the user.
The identity of the tweet to be read by each read request is generated based on the read frequencies that are randomly assigned to the tweets in the sample. These frequencies are generated from a Zipf distribution. Once a particular tweet has been chosen for a read request, the choice of whether to read on the primary or the secondary attribute value is based on the primary-to-secondary-reads ratio. The primary-to-secondary-reads ratio is a parameter that is set by the user. Users may choose to set this ratio to an arbitrarily large number if they do not wish to generate read requests for a secondary attribute value. Users must also specify the primary and secondary attributes to use. The default values are 'ID' for the primary and 'UserID' for the secondary attributes.
Users may also specify a speedup parameter. Each tweet has a 13-digit UNIX-time timestamp (milisecond precision). The benchmark file that is generated also has a timestamp (with milisecond precision) for each read or write request. The speedup factor divides the time intervals between consecutive requests. The higher the value of the speedup parameter, the smaller are the timestamps values and the closer together are the requests in the benchmark file. Varying the speedup factor allows you to increase or decrease the request rate on your key value store.
Using Chirp
Chirp currently runs on Linux and can be executed as a command line script. Chirp requires Python 2.7 or higher. We also recommend that you have the UltraJSON 1.33 JSON parser package for Python installed.
The first thing you need to use Chirp, is a sample of tweets to generate the benchmark. You can obtain a sample using the Twitter Streaming API. Chirp assumes that there is one JSON tweet object per line of the sample file. The zip file that is provided contains a small sample of tweets that you can use to test Chirp. A sample script is also included that runs Chirp on the tweet sample with default parameter values.
Chirp sorts the sample file based on the timestamp field ("CreationTime" attribute for tweets). Users can specify the memory buffer size for the sorting as a parameter. Users can also indicate whether they wish to keep the intermediate sorted file that is created and whether the input sample file is pre-sorted.
Please use the help option ('./chirp.py --help') to see all the parameters that are available.
Example
Obtain a sample of tweets. In the example below, we use the 'tweet_sample.txt' file that is provided in the zip file.
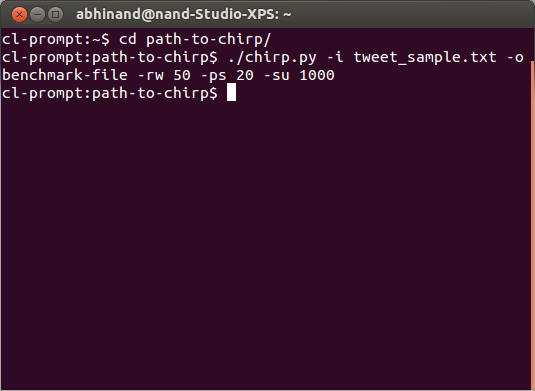
Run the Chirp script with desired parameters. In the example, below we use 'tweet_sample.txt' as the input file, 'benchmark-file' as the desired output file name, 50 as the reads-to-write ratio, 20 as the primary-to-secondary-reads ratio, and 1000 as the speedup value.
Your benchmark file is now ready.